Thiết bị đeo hỗ trợ nói nhờ AI
Những người bị rối loạn giọng nói - bao gồm cả những người mắc bệnh lý về dây thanh âm hoặc đang hồi phục sau phẫu thuật ung thư thanh quản - thường cảm thấy khó khăn hoặc không thể nói được. Điều đó có thể sớm thay đổi.
Một nhóm kỹ sư của UCLA vừa phát minh ra một thiết bị mềm, mỏng, co giãn có kích thước chỉ hơn 6cm vuông, gắn vào vùng da bên ngoài cổ họng nhằm giúp những người bị rối loạn chức năng dây thanh âm lấy lại chức năng giọng nói. Hệ thống điện sinh học mới, được phát triển bởi Jun Chen, trợ lý giáo sư kỹ thuật sinh học tại Trường Kỹ thuật UCLA Samueli và đồng nghiệp, phát hiện chuyển động trong cơ thanh quản của một người và chuyển những tín hiệu đó thành giọng nói nghe được với sự hỗ trợ của máy - công nghệ học tập - với độ chính xác gần 95%.
Bước đột phá này là nỗ lực mới nhất của Chen nhằm giúp đỡ những người khuyết tật. Nhóm của ông trước đây đã phát triển một chiếc găng tay đeo được có khả năng dịch Ngôn ngữ ký hiệu của Mỹ sang giọng nói tiếng Anh trong thời gian thực giúp người dùng ASL giao tiếp với những người không biết cách ký hiệu.
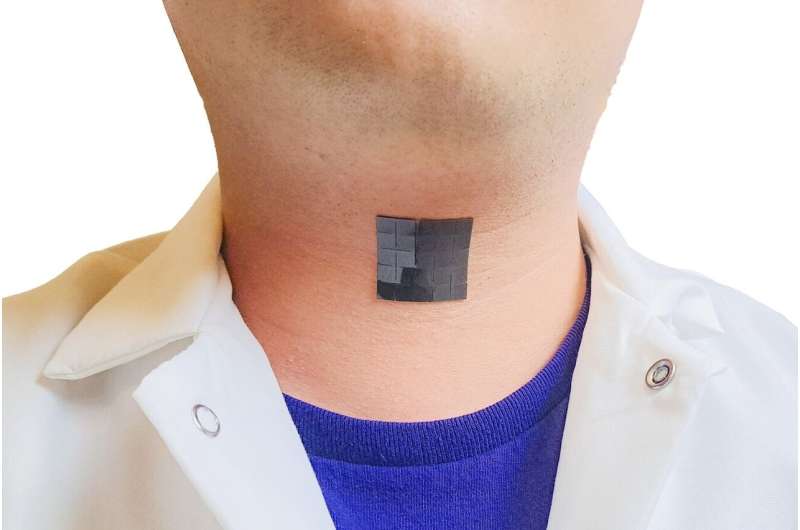
Ngôn ngữ ký hiệu Mỹ (ASL) là ngôn ngữ dấu hiệu chiếm ưu thế của cộng đồng người khiếm thính tại Mỹ và hầu hết tại vùng Canada nói tiếng Anh. Thiết bị nhỏ giống như miếng vá mới này được tạo thành từ hai thành phần. Một, thành phần cảm biến tự cấp nguồn, phát hiện và chuyển đổi tín hiệu được tạo ra bởi chuyển động của cơ thành tín hiệu điện có độ chính xác cao, có thể phân tích được; những tín hiệu điện này sau đó được dịch thành tín hiệu giọng nói bằng thuật toán học máy. Phần còn lại, thành phần truyền động, biến tín hiệu giọng nói đó thành biểu thức giọng nói mong muốn. Hai thành phần này, mỗi thành phần chứa hai lớp: một lớp hợp chất silicone polydimethylsiloxane, hay PDMS, có đặc tính đàn hồi và một lớp cảm ứng từ làm bằng cuộn cảm ứng bằng đồng.
Kẹp giữa hai thành phần là lớp thứ năm chứa PDMS trộn với nam châm micro, tạo ra từ trường. Bằng cách sử dụng cơ chế cảm biến từ tính đàn hồi mềm do nhóm của Chen phát triển vào năm 2021, thiết bị này có khả năng phát hiện những thay đổi trong từ trường khi nó bị thay đổi do lực cơ học - trong trường hợp này là chuyển động của cơ thanh quản. Các cuộn dây cảm ứng ngoằn ngoèo được nhúng trong các lớp đàn hồi từ tính giúp tạo ra loạt tín hiệu điện có độ chính xác cao cho mục đích cảm biến.
Thiết bị nặng khoảng 7 gram và chỉ dày 1,5mm. Với băng tương thích sinh học hai mặt, nó có thể dễ dàng bám vào cổ họng của một người gần vị trí của dây thanh âm và có thể được tái sử dụng bằng cách dán lại băng khi cần thiết. Rối loạn giọng nói phổ biến ở mọi lứa tuổi và nhóm nhân khẩu học; nghiên cứu đã chỉ ra rằng gần 30% số người sẽ trải qua ít nhất một chứng rối loạn như vậy trong đời. Tuy nhiên, với những phương pháp trị liệu, chẳng hạn như can thiệp bằng phẫu thuật và trị liệu bằng giọng nói, quá trình phục hồi giọng nói có thể kéo dài từ ba tháng đến một năm, với một số kỹ thuật xâm lấn đòi hỏi phải có một khoảng thời gian đáng kể để nghỉ ngơi sau phẫu thuật.

Chen, người đứng đầu Nhóm nghiên cứu điện tử sinh học có thể đeo tại UCLA và được vinh danh là một trong những nhà nghiên cứu được trích dẫn nhiều nhất trên thế giới trong 5 năm qua, cho biết: “Các giải pháp hiện tại như thiết bị điện thanh quản cầm tay và thủ thuật chọc khí quản có thể gây bất tiện, xâm lấn hoặc không thoải mái. Thiết bị mới mang đến một lựa chọn có thể đeo được, không xâm lấn, có khả năng hỗ trợ bệnh nhân giao tiếp trong giai đoạn trước khi điều trị và trong giai đoạn phục hồi sau điều trị đối với chứng rối loạn giọng nói”.
Trong loạt thí nghiệm, nhóm nhà nghiên cứu thử nghiệm công nghệ thiết bị đeo trên 8 người trưởng thành khỏe mạnh. Họ thu thập dữ liệu về chuyển động của cơ thanh quản và sử dụng thuật toán học máy so sánh loạt tín hiệu thu được với một số từ nhất định. Sau đó, họ chọn tín hiệu giọng nói đầu ra tương ứng thông qua thành phần truyền động của thiết bị.
Nhóm nghiên cứu chứng minh tính chính xác của hệ thống bằng cách yêu cầu những người tham gia phát âm một số câu - cả to và không thành tiếng - bao gồm “Xin chào, Rachel, hôm nay bạn thế nào?” và “Tôi yêu bạn!” Độ chính xác dự đoán tổng thể của mô hình là 94,68%, với tín hiệu giọng nói của người tham gia được khuếch đại bởi thành phần truyền động, chứng tỏ cơ chế cảm biến nhận ra tín hiệu chuyển động thanh quản của họ và khớp với câu tương ứng mà người tham gia muốn nói. Trong tương lai, nhóm nghiên cứu có kế hoạch tiếp tục mở rộng vốn từ vựng của thiết bị thông qua học máy và thử nghiệm ở những người bị rối loạn ngôn ngữ.
 Da điện tử - thiết bị đeo tương lai
Da điện tử - thiết bị đeo tương lai  Thiết bị đeo biến cái chạm của ngón tay thành nguồn năng lượng
Thiết bị đeo biến cái chạm của ngón tay thành nguồn năng lượng